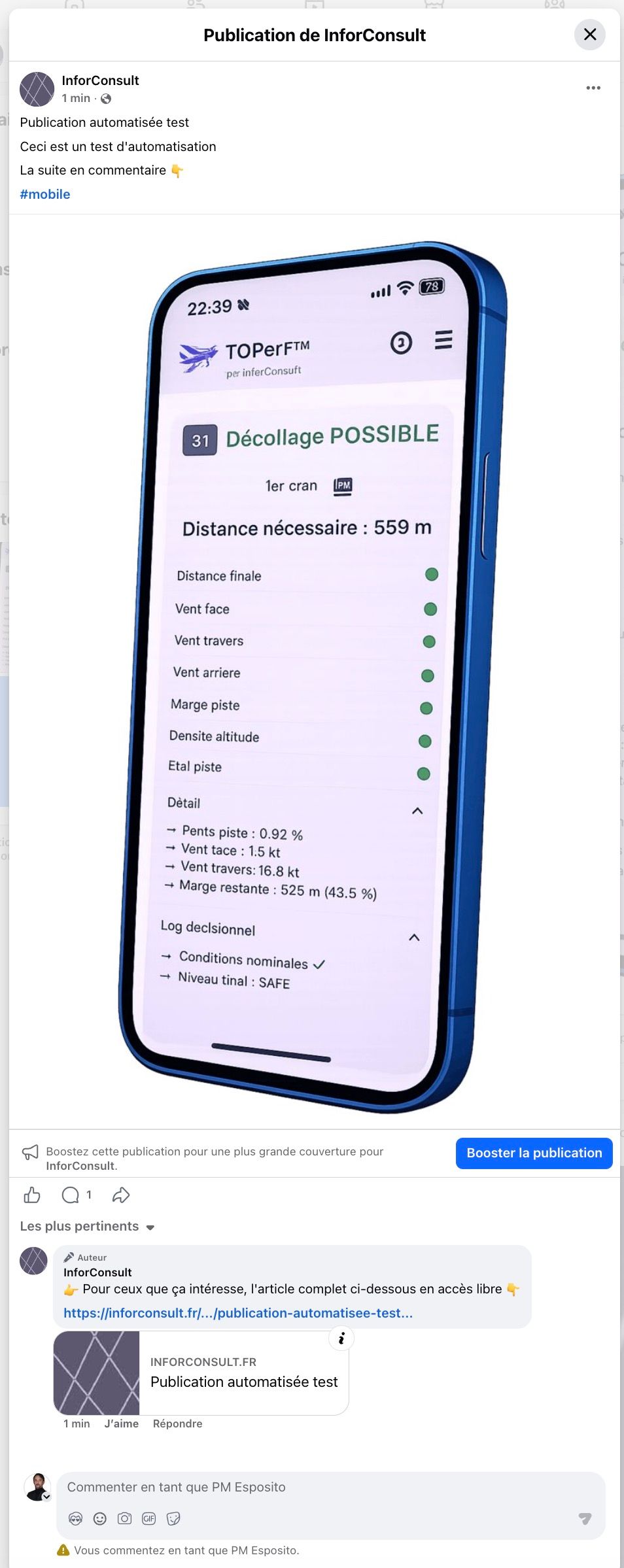
J'ai mis en ligne un diagnostic informatique gratuit en 3 minutes pour les dirigeants de PME/ETI
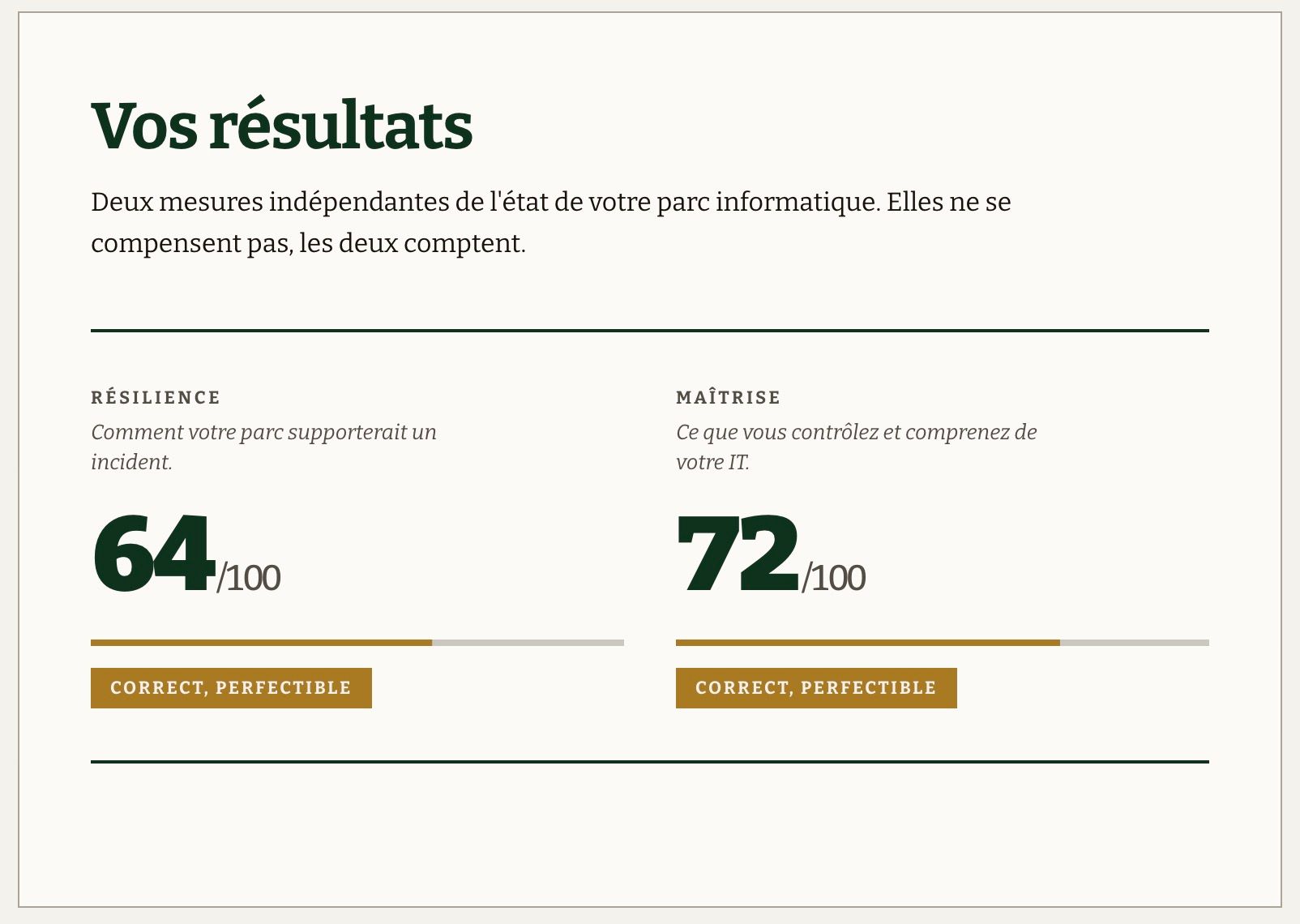
📊 "On a un antivirus, une sauvegarde... on doit être à peu près protégés." C'est ce que pensent la plupart des dirigeants de PME que je rencontre. Et la plupart du temps, personne n'a vraiment vérifié. Je viens de mettre en ligne un outil gratuit qui répond à cette question en 3 minutes chrono : un diagnostic de votre parc informatique (sauvegarde, sécurité, supervision, budget), qui vous donne un score, vos points de fragilité prioritaires et des conseils concrets pour les corriger, gratuitement, sans rendez-vous, sans carte bancaire, sans engagement. C'est le point de départ que j'aurais aimé donner à chaque PME avant qu'un incident ne les force à se poser la question.
Le problème : personne ne vérifie, jusqu'au jour où ça casse
Dans la plupart des PME que j'accompagne ou que je rencontre, la question "êtes-vous bien protégés informatiquement ?" reçoit une réponse honnête mais floue : "je crois", "normalement oui", "je ne sais pas trop, c'est mon prestataire qui gère". Personne n'a de mauvaise volonté, c'est juste qu'aucun outil simple ne permettait jusqu'ici de faire le point sans déjà s'engager dans un audit complet.
L'outil : un diagnostic en 3 minutes, pas un audit déguisé
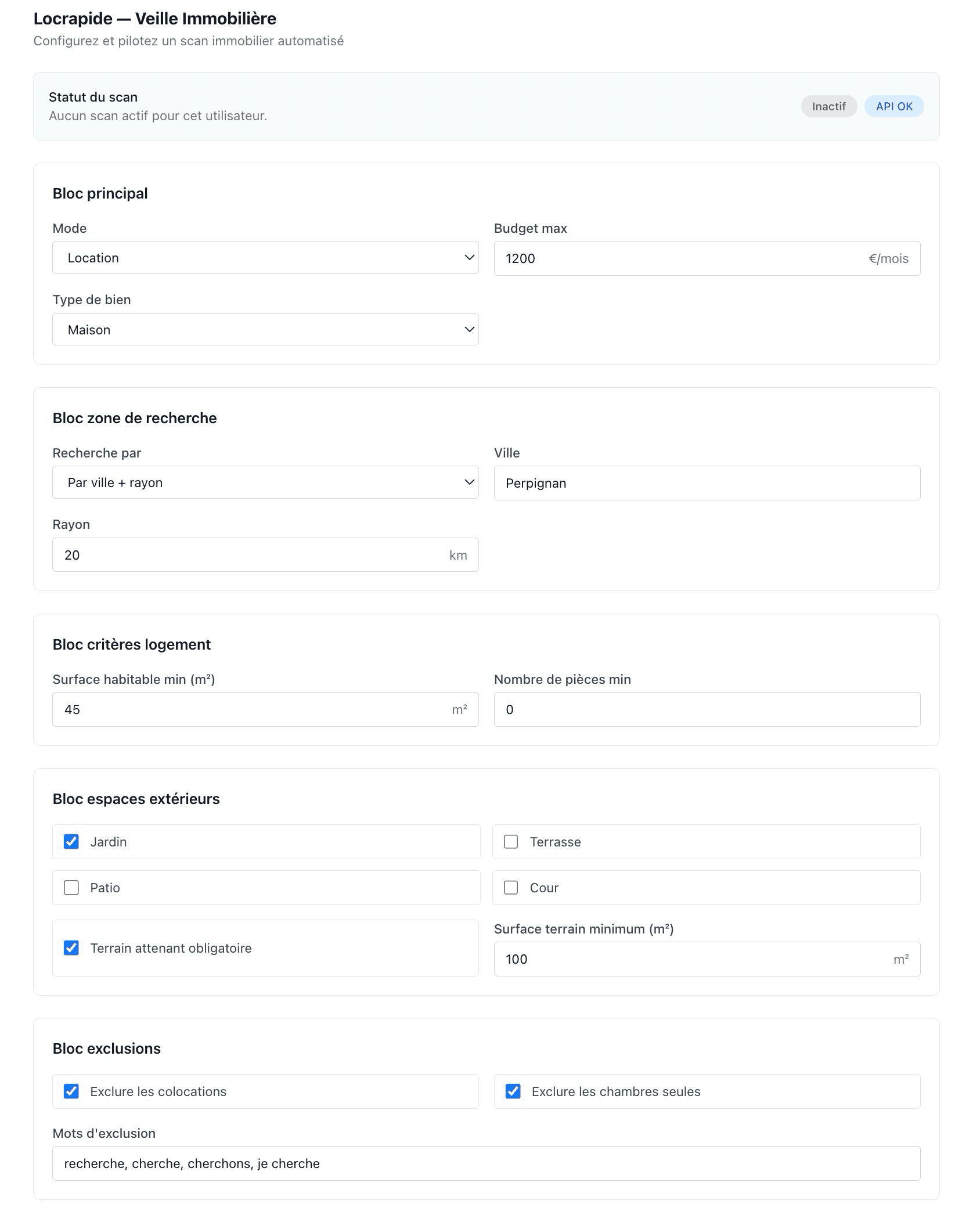
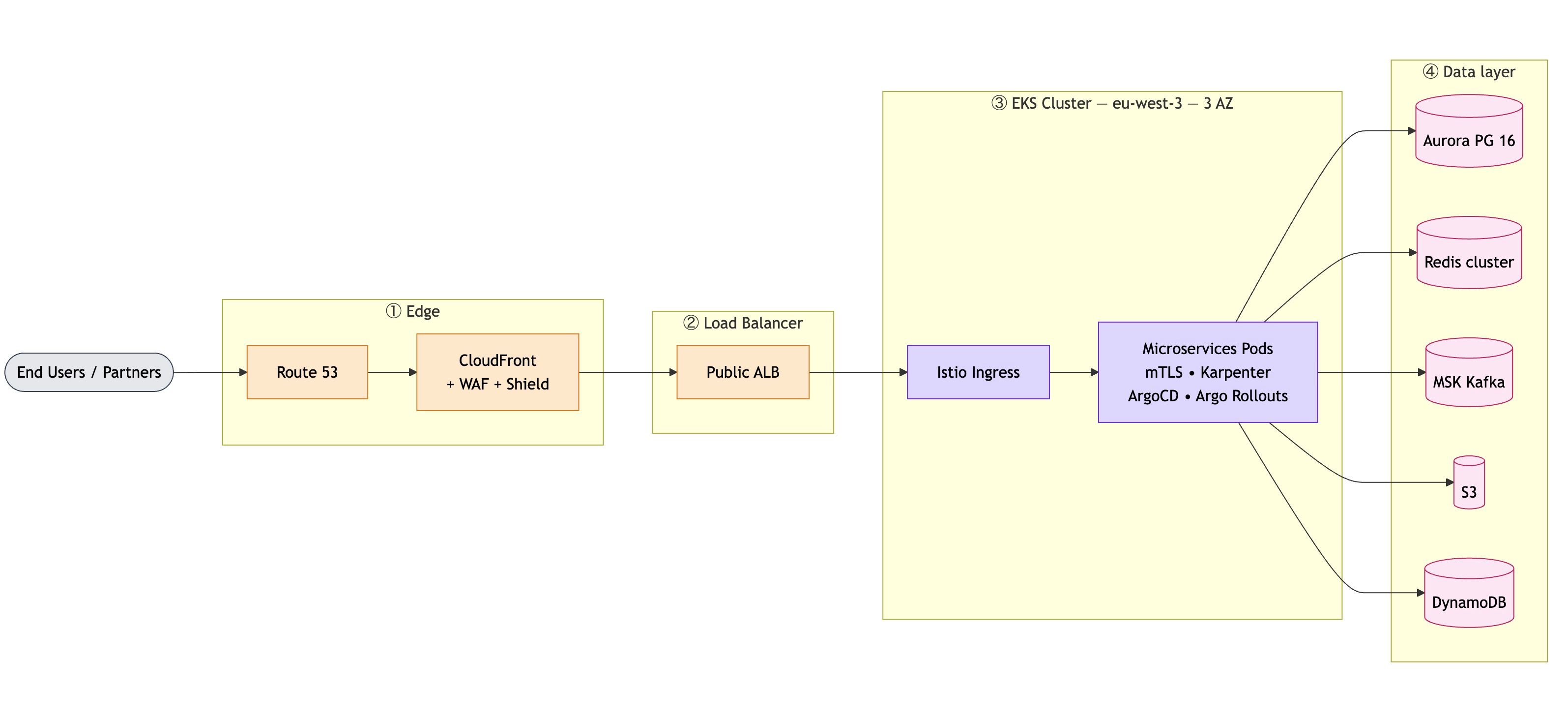
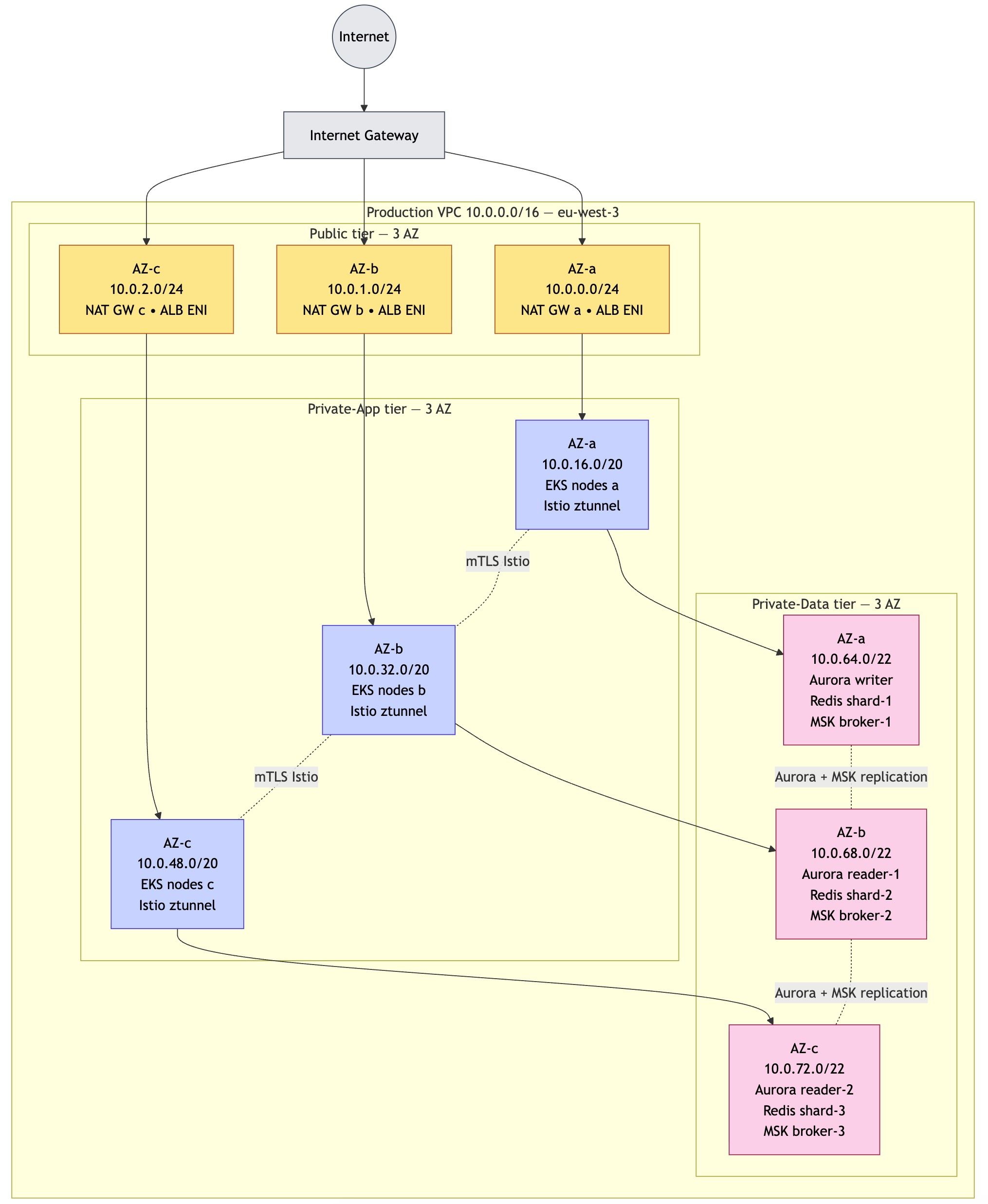
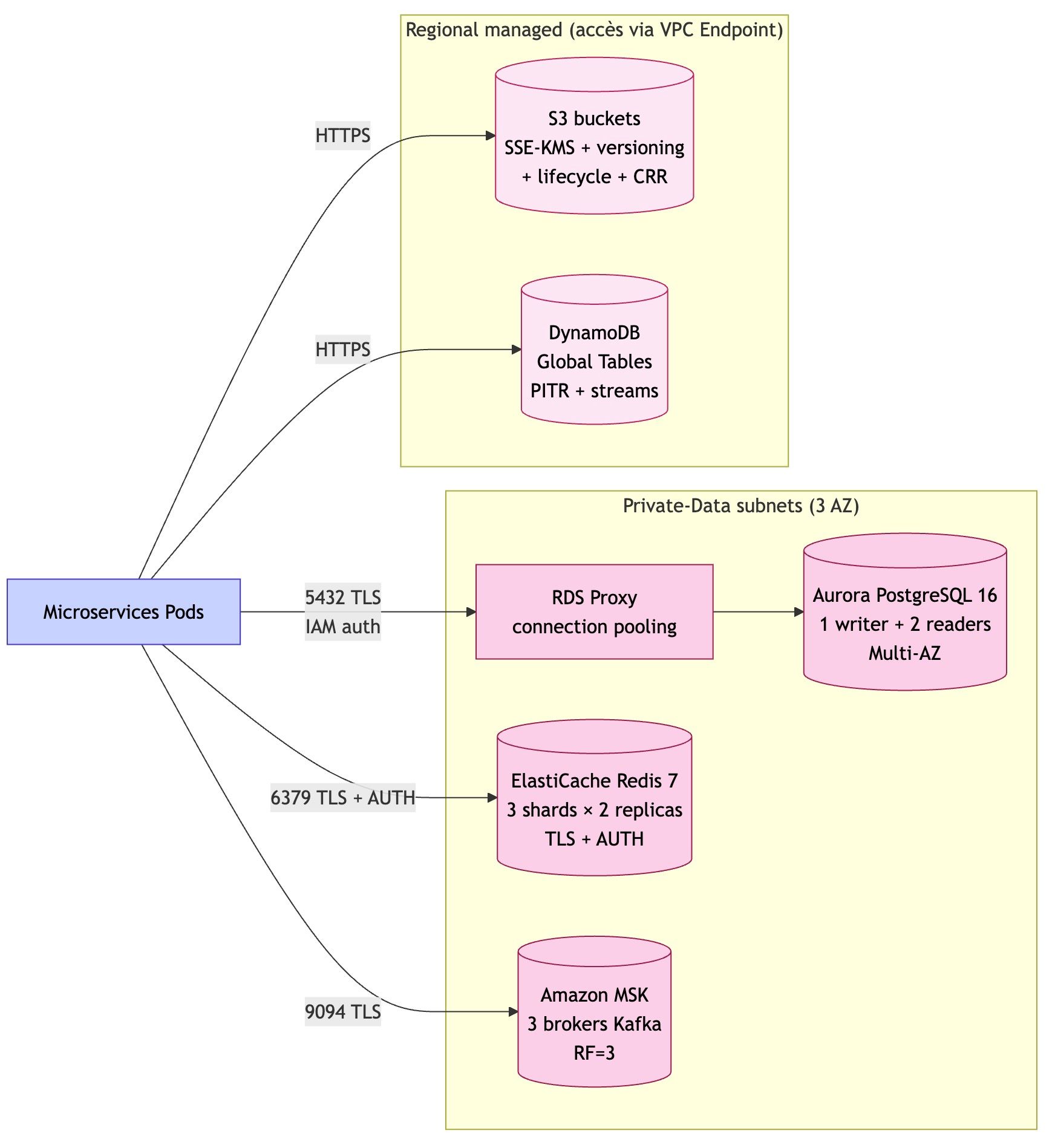
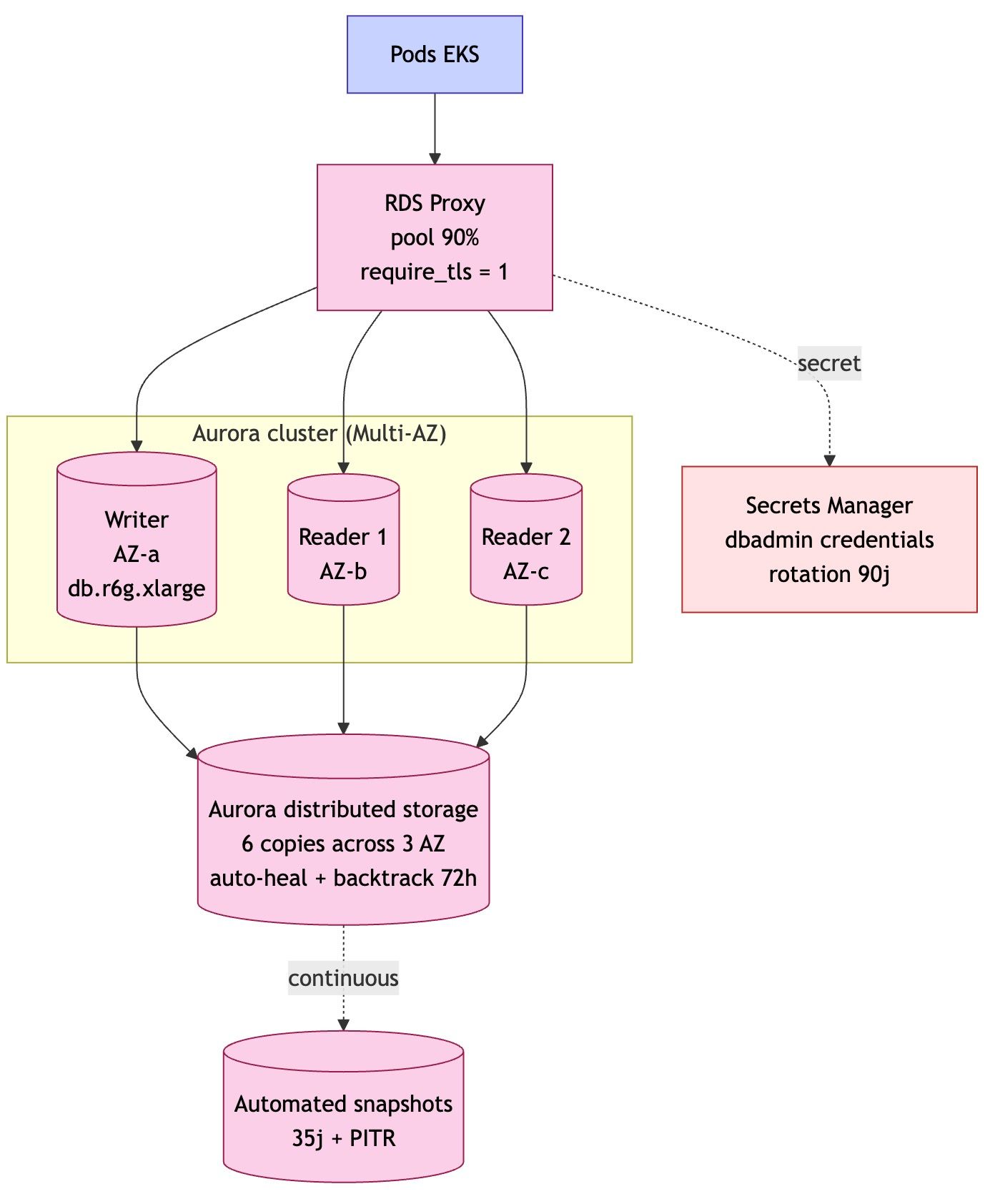
C'est pour ça que j'ai construit ce diagnostic, accessible sur infogerance.inforconsult.fr. Le principe : une quinzaine de questions simples (à choix, pas de champ à remplir), sur quatre thèmes :
- votre profil (taille de l'équipe, nombre de postes et de serveurs) ;
- votre sauvegarde (automatique ? protégée contre le ransomware ? déjà testée ?) ;
- votre sécurité (antivirus, mises à jour, double authentification) ;
- votre support actuel (supervision proactive ou découverte des pannes après coup, délai d'intervention).
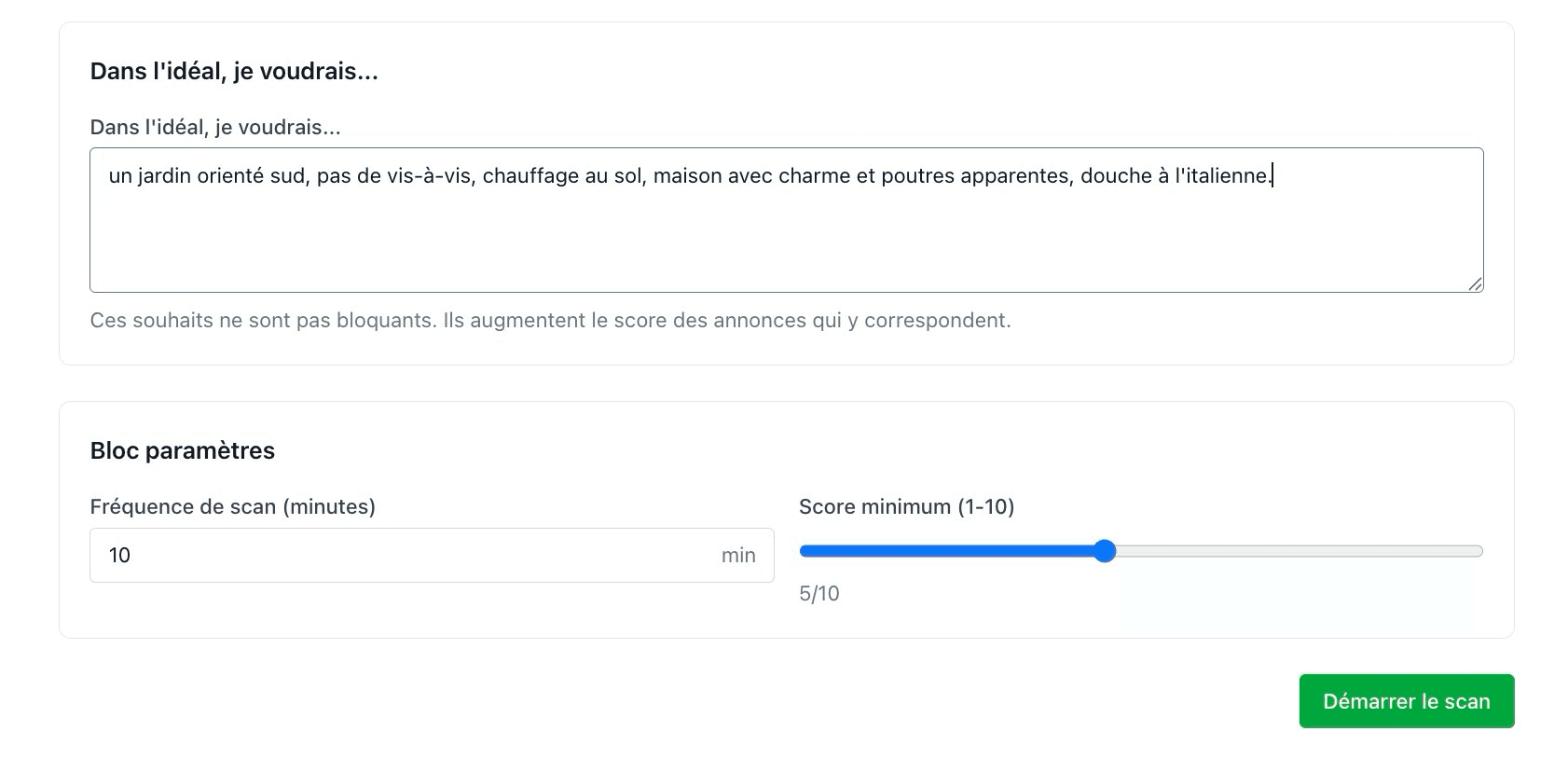
À la fin, deux scores s'affichent immédiatement : un score sécurité et un score de clarté budgétaire, sans même avoir donné d'email. Ce n'est qu'ensuite, pour débloquer le détail (points d'attention prioritaires et conseils concrets pour progresser), qu'un prénom et un email sont demandés.
Ce n'est pas un audit réel, et c'est assumé
Ce diagnostic ne remplace pas un vrai audit informatique. C'est un déclaratif : les réponses reposent sur ce que vous savez de votre parc, pas sur une inspection technique. Mais c'est justement là son intérêt : donner en 3 minutes une première photo honnête, là où un audit complet demande du temps et un rendez-vous. Le diagnostic débouche d'ailleurs naturellement vers l'audit gratuit que je propose déjà, sur site ou à distance, pour ceux qui veulent aller plus loin.
Pourquoi je le rends public maintenant
Beaucoup de dirigeants de PME reportent la question de la sécurité informatique parce qu'ils n'ont pas de point de départ clair : pas envie de prendre un rendez-vous juste pour "voir", pas le temps de creuser seul. Ce diagnostic supprime cette première friction, et surtout, il ne vend rien. Pas de tarif affiché, pas de forfait poussé en fin de parcours : uniquement des conseils concrets et gratuits, adaptés à vos réponses, pour améliorer dès aujourd'hui ce qui peut l'être par vous-même (activer une double authentification, tester une restauration, revoir la fréquence de vos sauvegardes...).
Envie de savoir où vous en êtes, en 3 minutes et sans engagement ? Le diagnostic est accessible ici : https://infogerance.inforconsult.fr/ . Il vous dira exactement où sont vos points de fragilité, avant qu'un incident ne s'en charge à votre place.
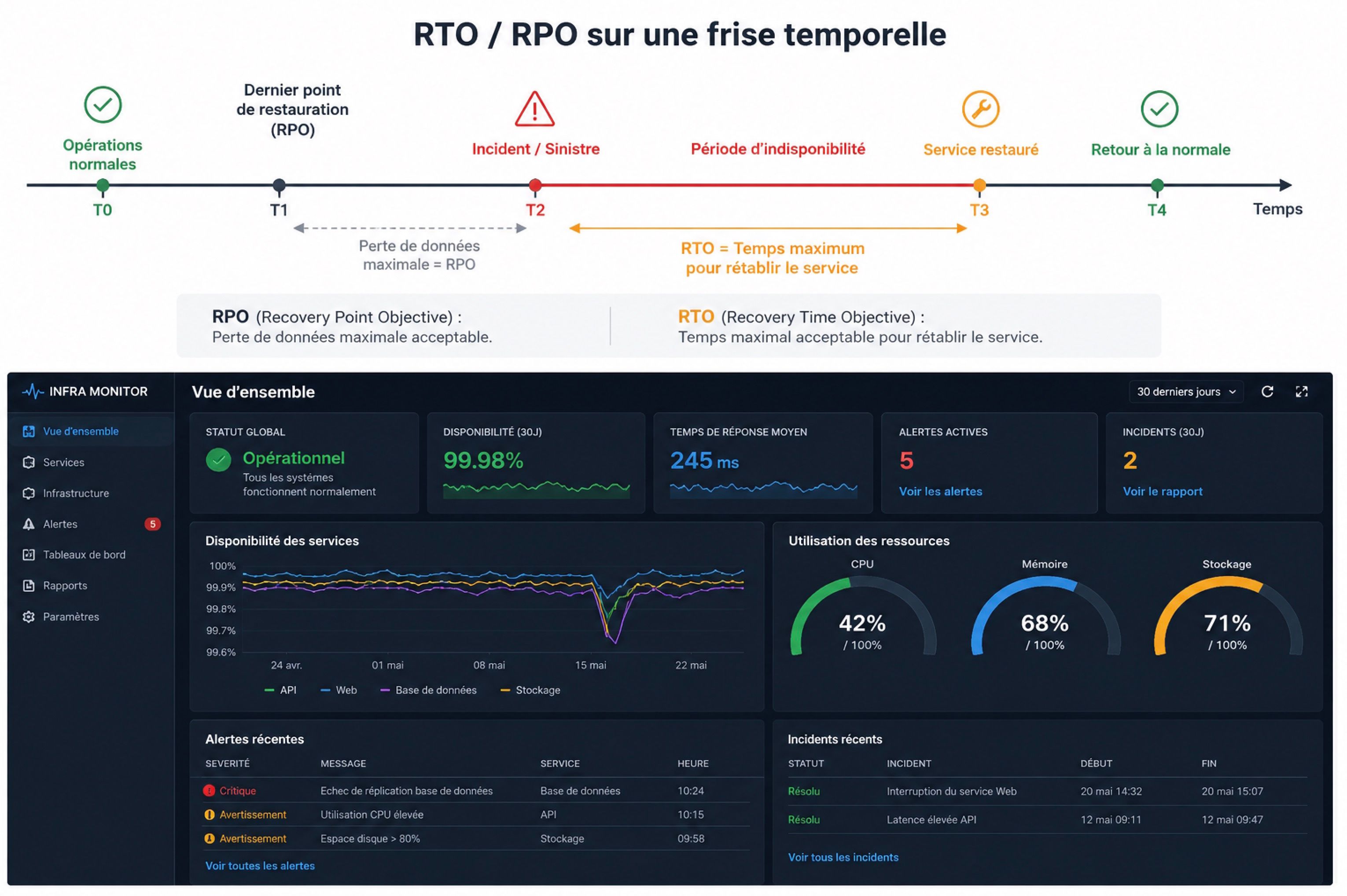






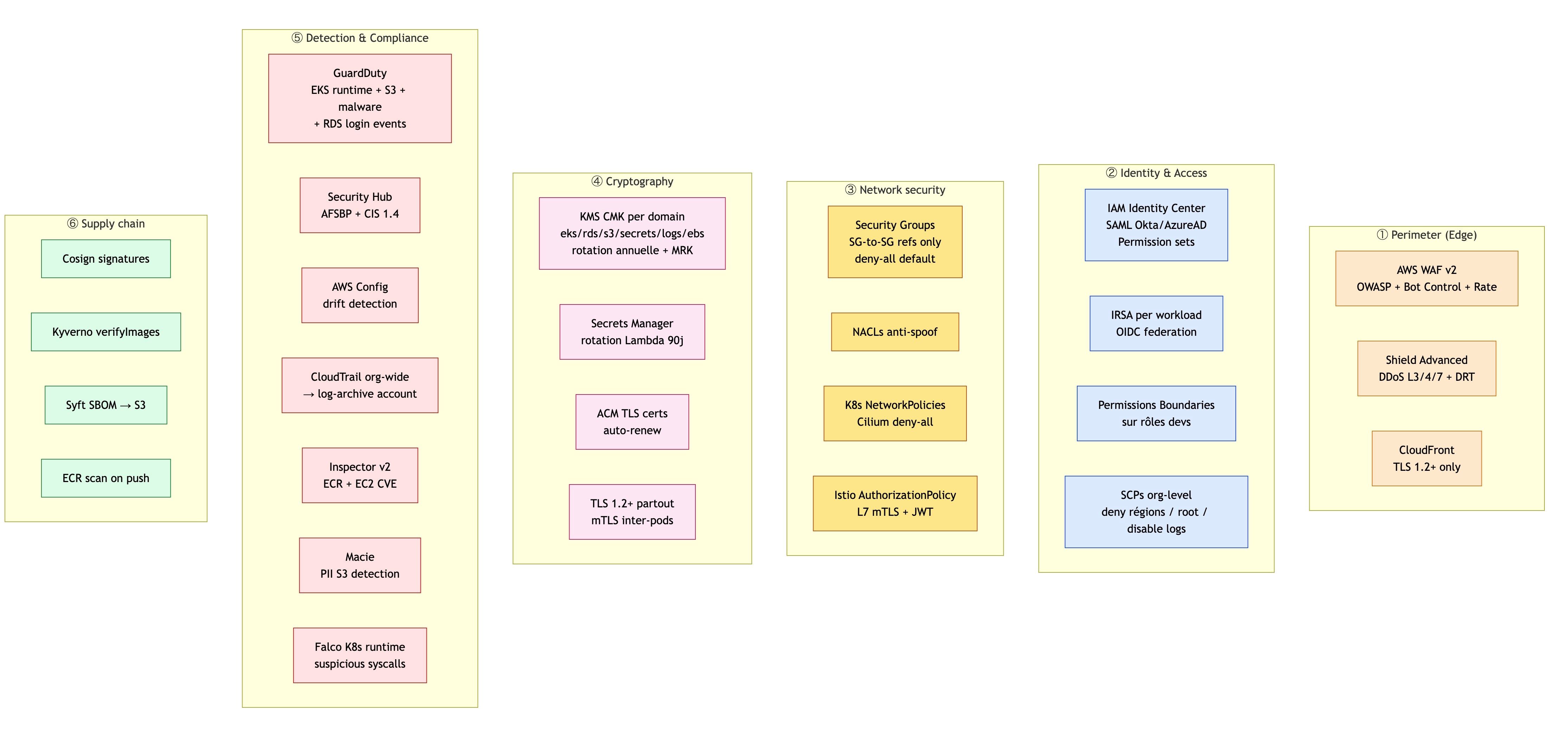
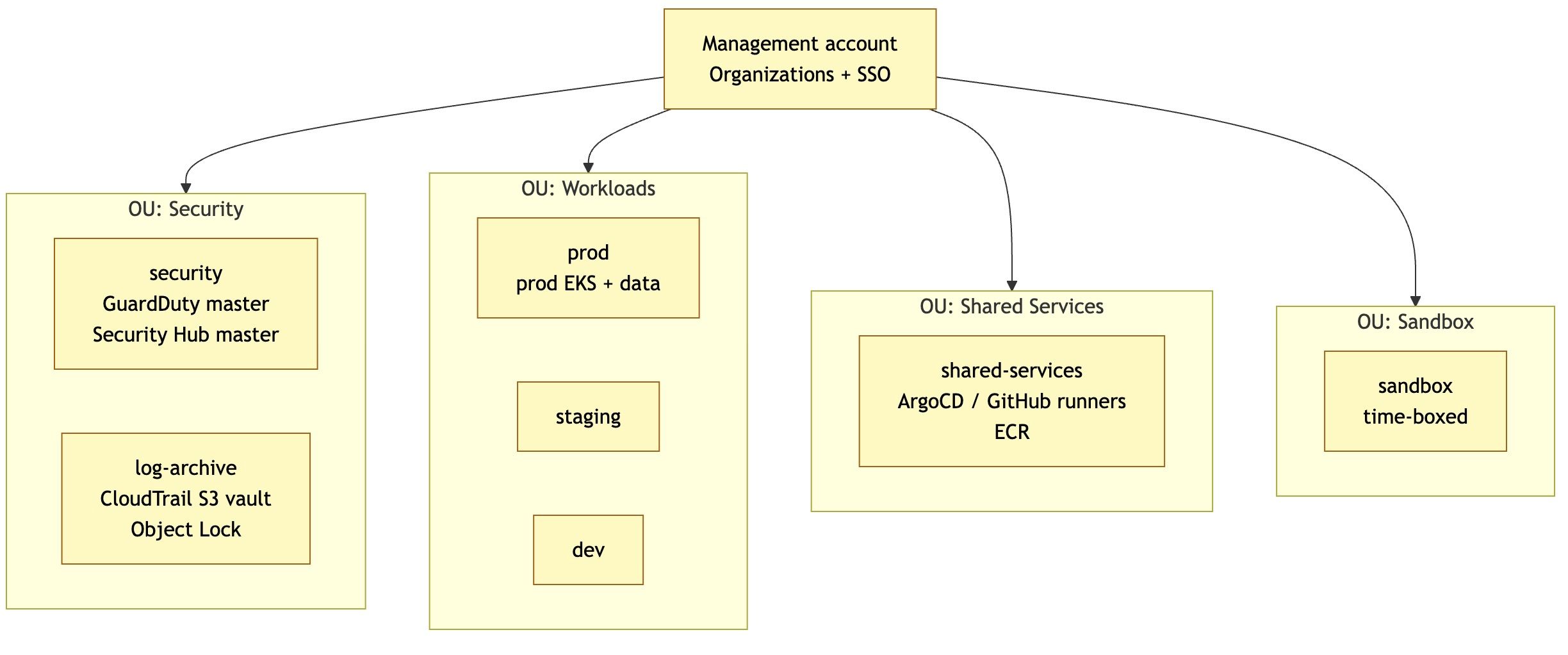
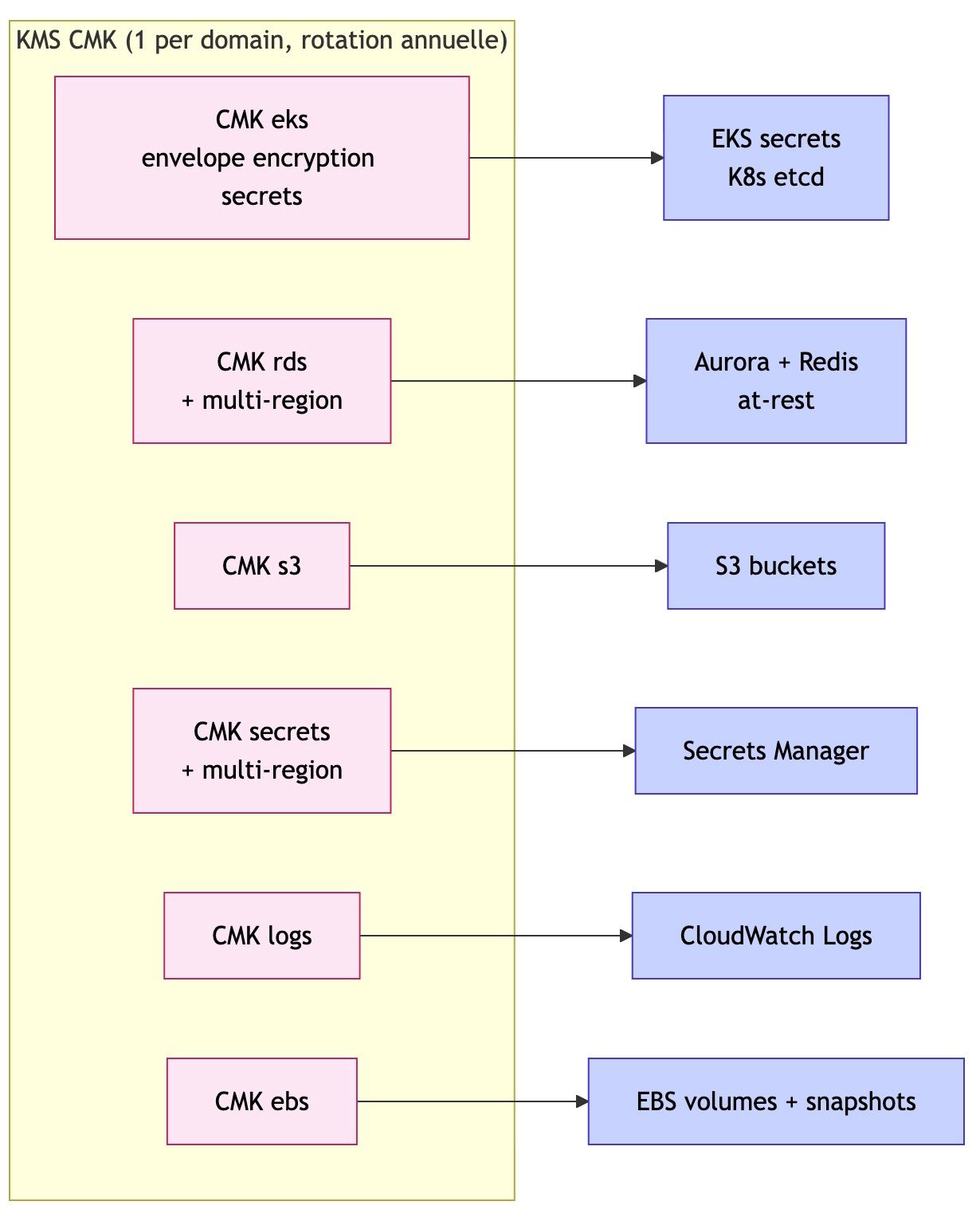
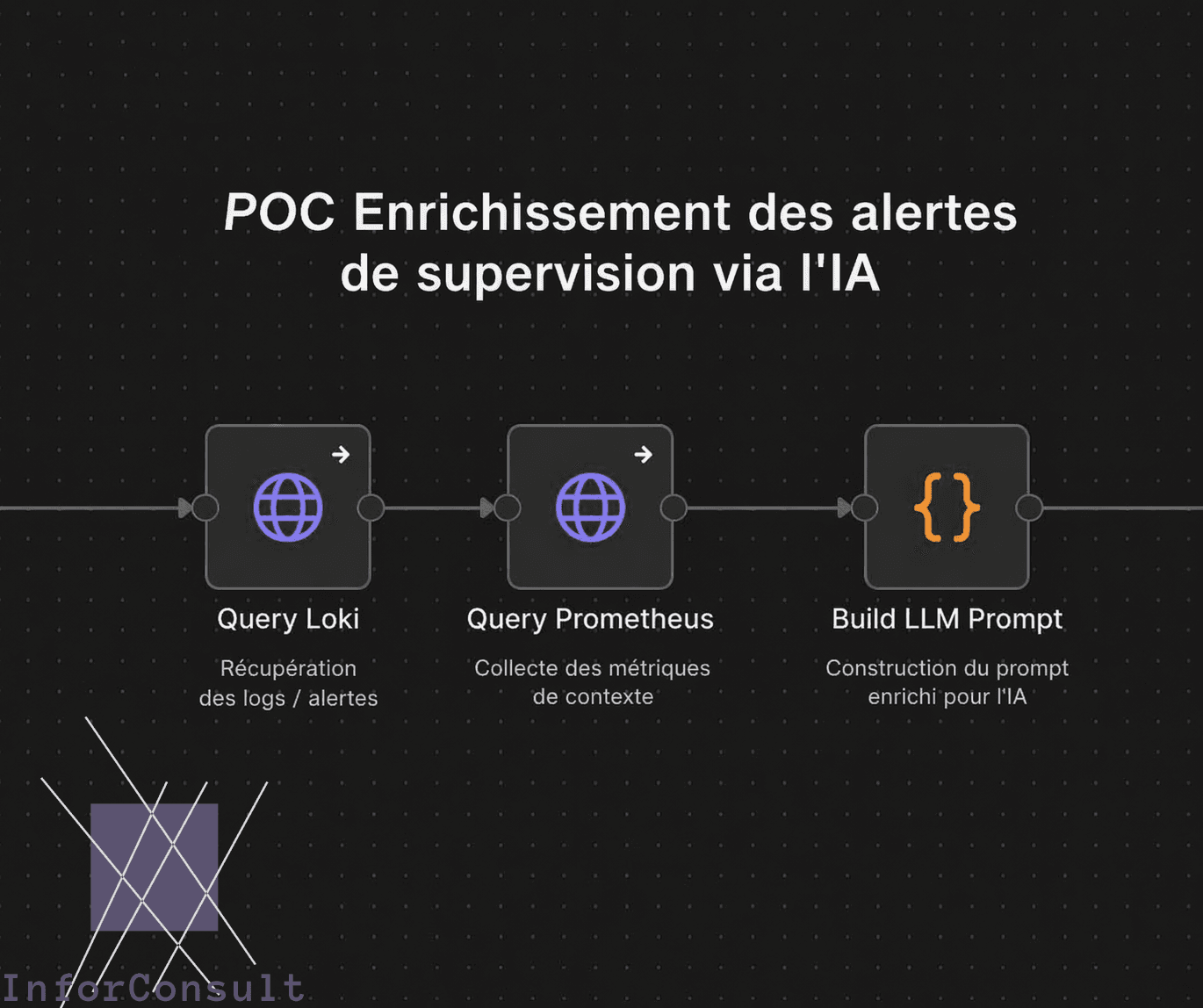

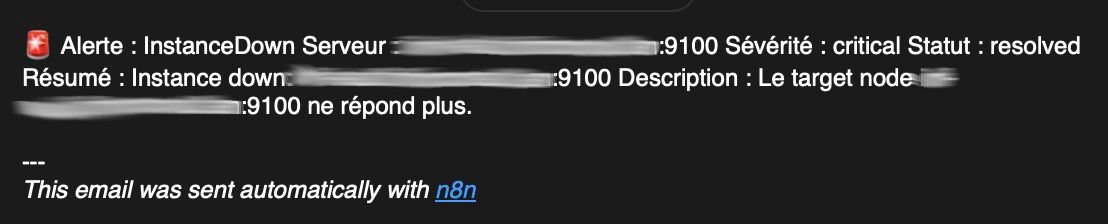
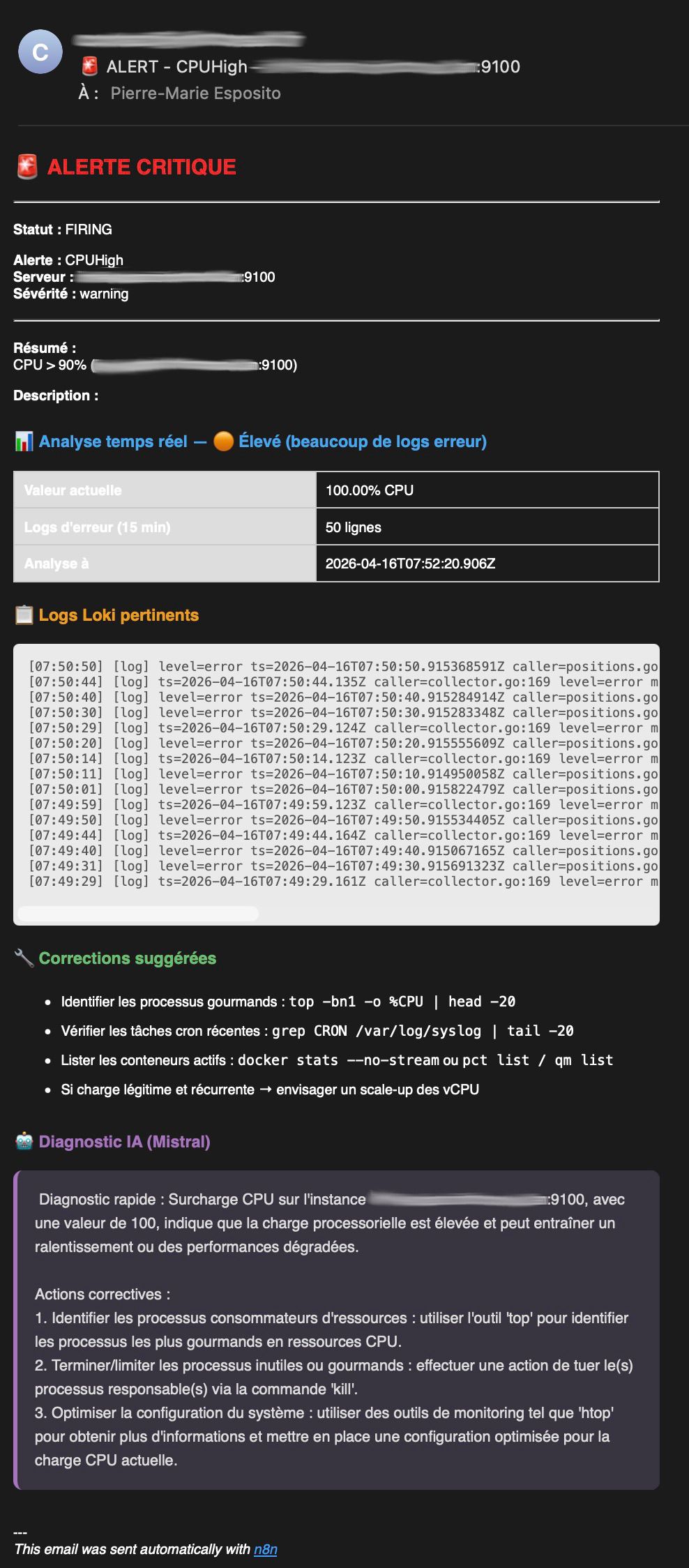
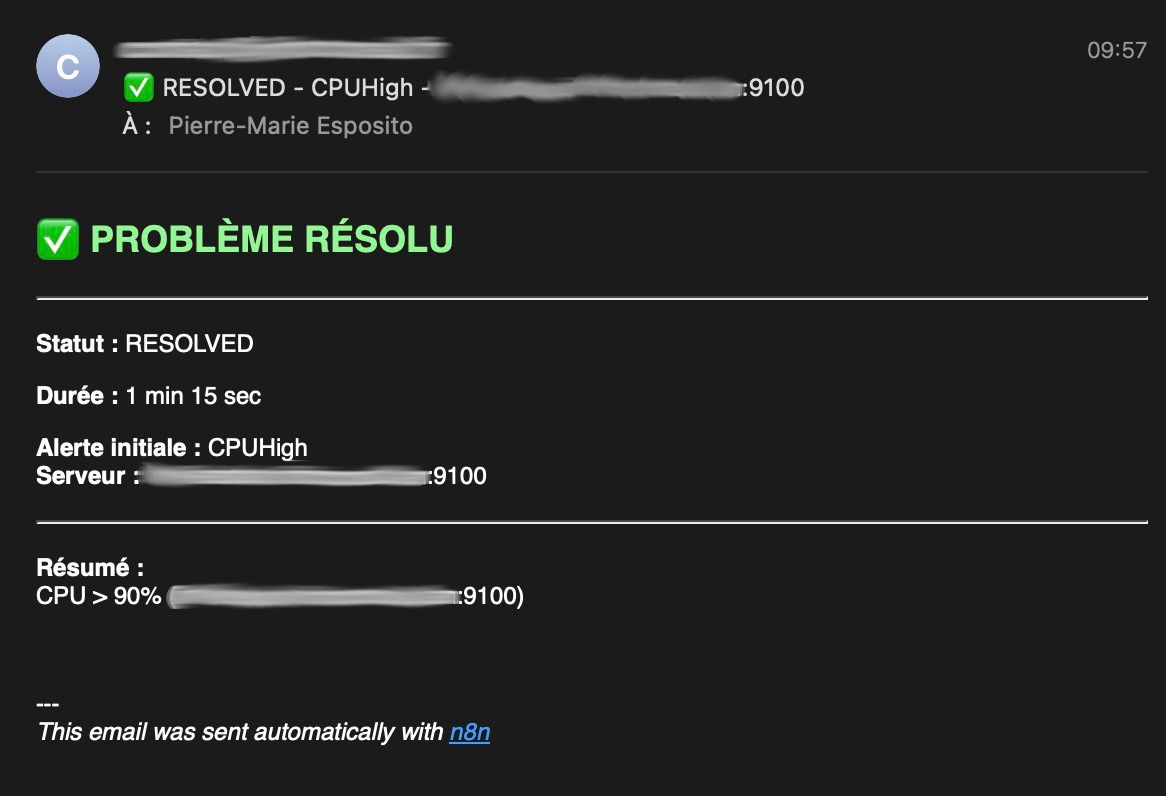
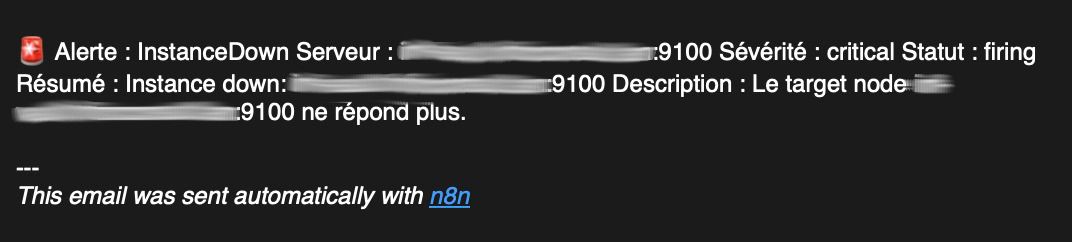 Email de résolution avant retraitement :
Email de résolution avant retraitement :
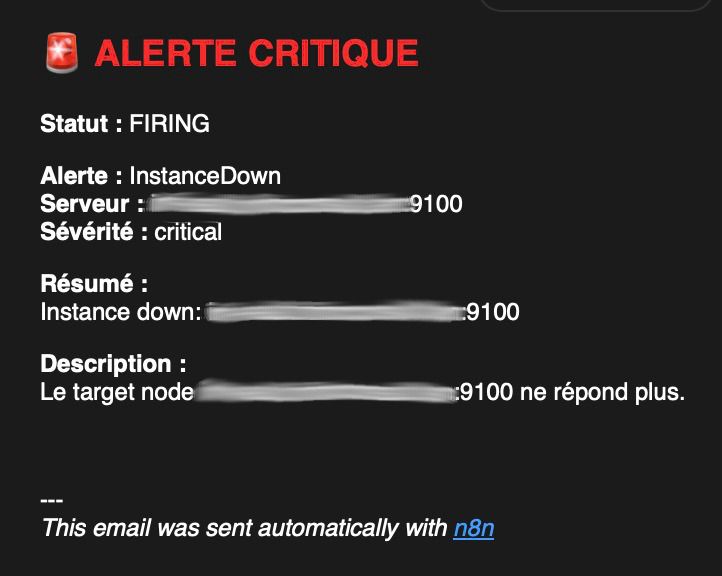
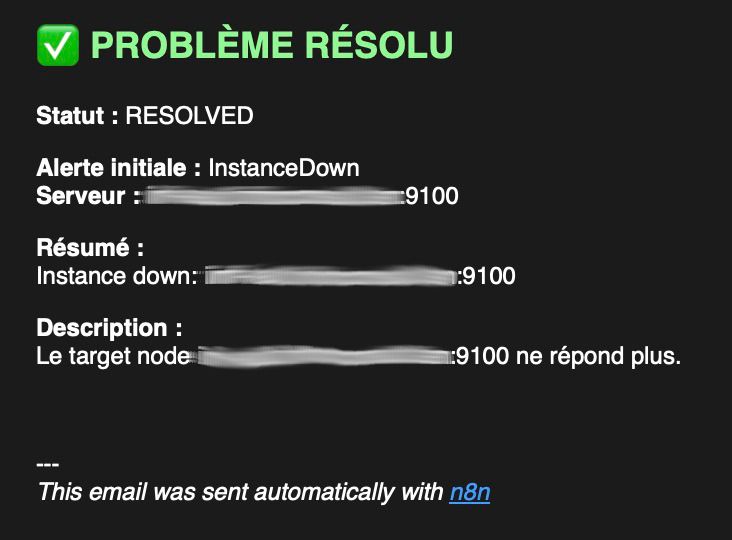
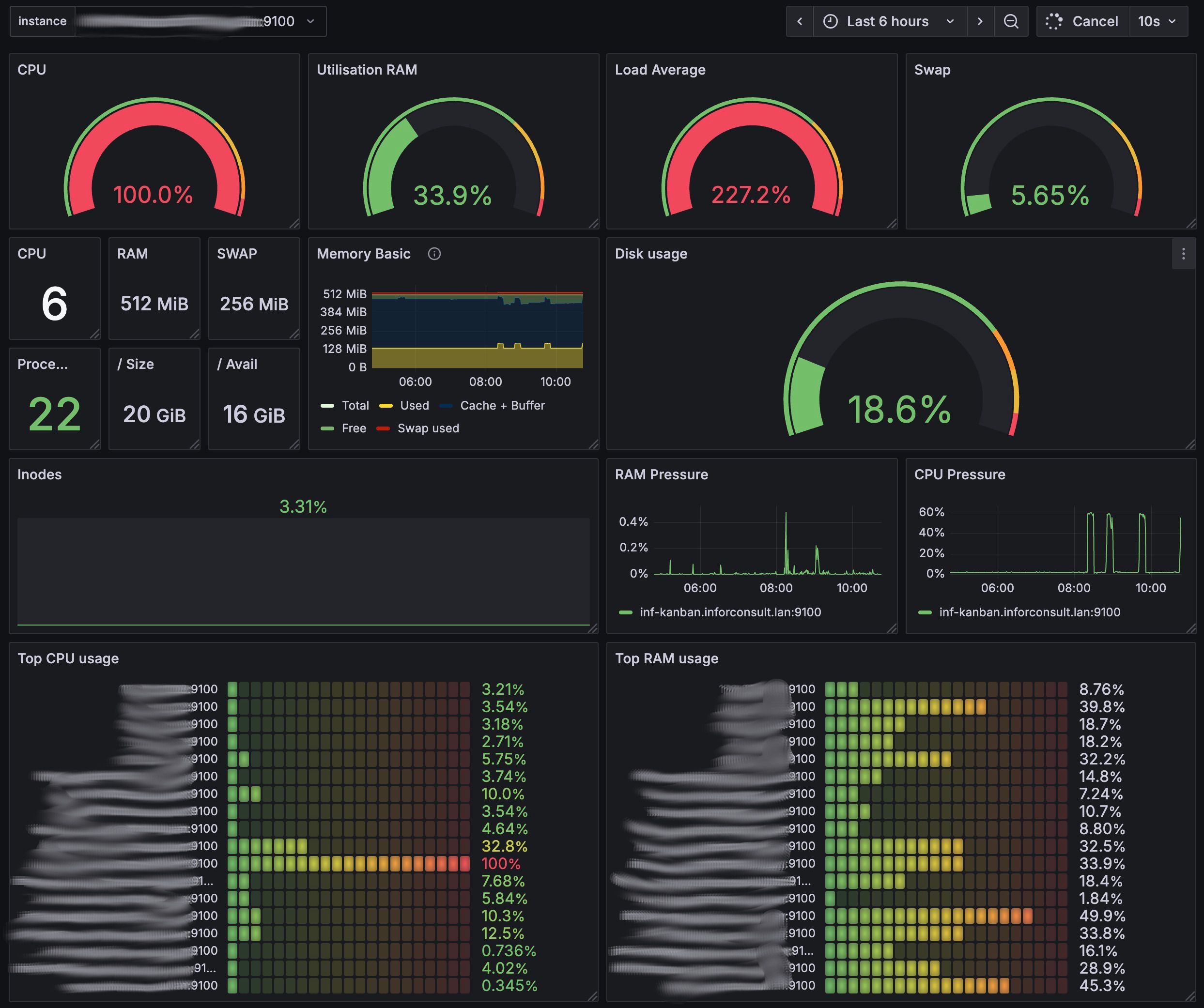 Intégration du LLM : choix et contraintes
Intégration du LLM : choix et contraintes